前言
最近重构了一下RavelloH/EverydayNews,这是一个每日60s新闻的存档项目兼API,之前是2022年用Python写的,之后一直没怎么管,bug也是缝缝补补上来的,其搜索功能是沿用的RavelloH/RPageSearch at v1,算是我很早之前写的黑历史了(现在让我写这种"面向字符串"的实现我还真写不出来了)
 是的,甚至手动拼接json
是的,甚至手动拼接json
如果我没记错的话,搜索应该几年前就坏了,而且因为是部署到Github Pages上,想要搜索也只能浏览器端fetch所有的数据,由本地JavaScript进行搜索。虽然之后我用JS重构了一下RavelloH/RPageSearch: 实现自动化静态站全站搜索 - 高性能/实时搜索/正则语法支持/异步/web worker/自动持续构建/可拓展数据格式/自定义前端样式,但是这三年的数据量已经到1.65MB了,每次搜索都要获取这么多数据确实很不优雅。
重构之后我也不考虑放到服务器上来运行搜索,毕竟内容不是我的,没法确保其中有没有什么雷点,于是重新写了个全新版本的静态搜索工具,实测性能提升高达13157%,太优雅了。
基于其运行原理,我把它叫做"index-search”,已经放在Github与npmjs上了。
RavelloH/index-search: 单字字典倒排式关联索引的静态资源搜索方案 index-search - npm
原理
和它的名字一样,"index-search",先索引再搜索。 在索引的时候,使用非常极限的“字典倒排索引”生成每个字的索引,纯正的“字典倒排索引”是使用词语作为分隔的,因此适用于英文但对中文并不友好,毕竟中文的分词比英文麻烦的多。
尤其适合中文这种字种多的语言,对纯英文用处不大,如果考虑到并发请求的副作用的话效果甚至不如RPageSearch V2。主要对“不是每篇文章都能用到”的字有效果,且作为索引,只能告诉你哪个内容中有你输入的搜索词,要获取那篇文章的全文需要再自行请求。
我这里使用单个字来进行索引,即输入n篇文字,会给出n篇文字中出现过的所有中文、英文、数字字符,及其在这n篇文章中的哪些篇的哪些地方出现。非常好懂,看图即可:
 example
example
上图中是输入3组文字,生成其中包含的所有字符的索引,包含其出现在的文字的组即其在其中的index。
之后的事就是由前端来进行,获取相应的字符的索引表,检查其对应的文字组中的索引是否能与搜索词的上下文关联。前端的原理较长,放最后了。
性能
具体使用场景:EverydayNews - https://news.ravelloh.top
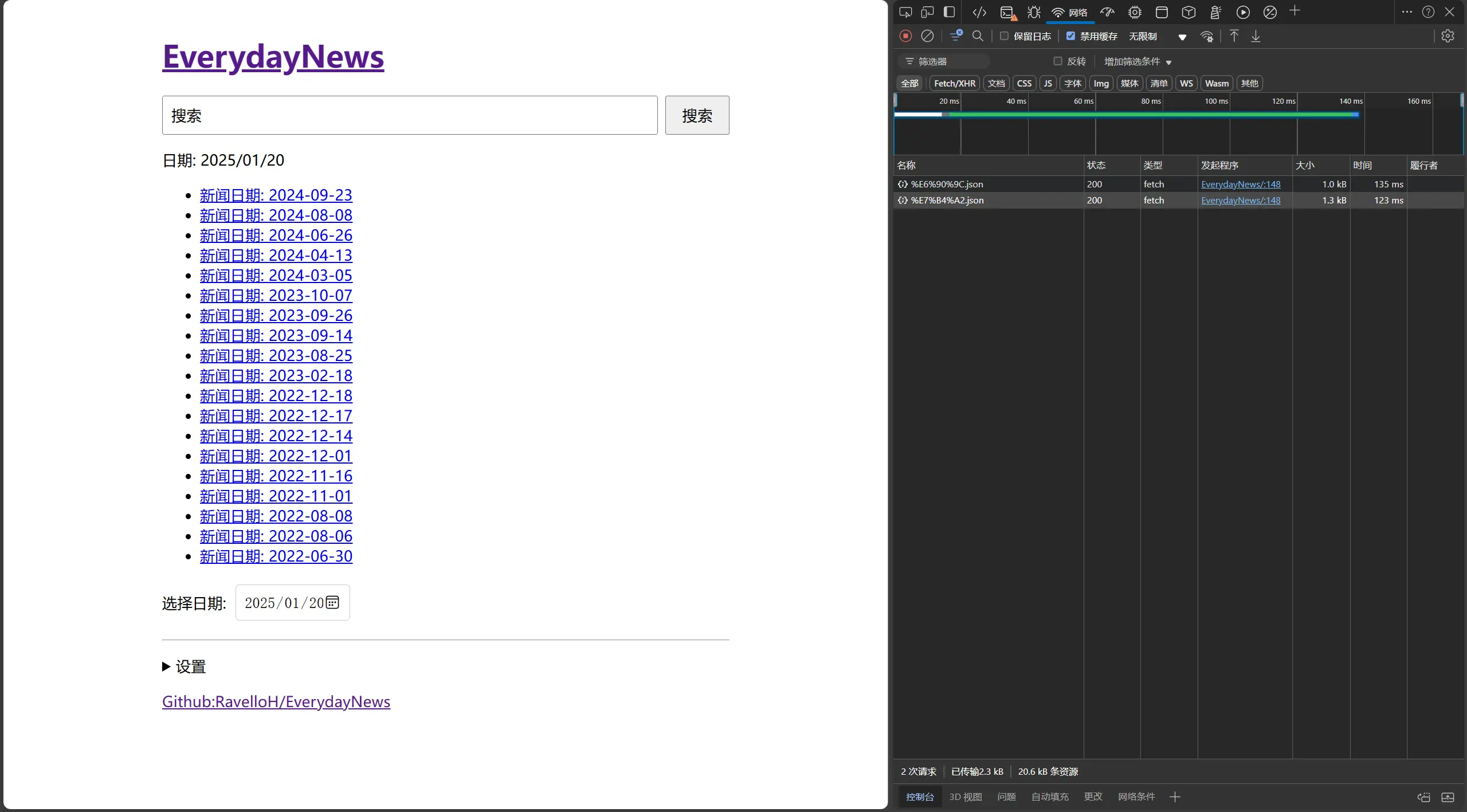 在大部分的搜索场景中,可提供近乎无感的搜索体验
在大部分的搜索场景中,可提供近乎无感的搜索体验
典型情况下,中文新闻语料库Github:RavelloH/EverydayNews的data文件夹大小为1,738,276字节(1.65MB)时,会生成25,184,701(24.0MB)字节的索引,包含3773个json文件,平均每个文件的大小为6674字节(6.51KB),需要请求的文件大小降低至原来的(字数*6674)/1738276。 在通常的中文搜索场景中,搜索词的长度在2-10之间。[来源:网络用户搜索行为特征分析] 典型赋值,字数为2-10时,降低至原来的0.0076-0.0383倍,提升高达2610%-13157%,效果显著。
实现
nodejs
npm i index-searchconst indexSearch = require("./index");
indexSearch.config.outputFolder = "search"; // 输出文件夹
indexSearch.data = [
{
content: "This is a test",
src: "/test",
},
{
content: "This is another test",
src: "/test2",
},
{
content: "这是中文字符的测试",
src: "/中文",
}
]
indexSearch.index();实际上因为indexSearch.data就是个数组,你可以在调用indexSearch.index();之前随便操作,例如就可以直接indexSearch.data.push(),方便异步操作。
data里面的信息仅需要content和src即可,为了减小文件体积请尽量使用简短的src。
前端
实际上前端实现的方式也很简单,就不放在包里了,直接用下面的函数即可。
async function search(words) {
if (!Array.isArray(words)) {
words = words.split('');
}
const total = words.length;
const charDataList = [];
const fetchPromises = words.map(async (char, idx) => {
try {
const res = await fetch(`/search/${char}.json`); // 根据你输出文件夹发路径设置
const json = await res.json();
charDataList[idx] = json.data;
} catch (error) {
console.error(`Error fetching ${char}:`, error);
}
});
await Promise.all(fetchPromises);
const resultMap = {};
charDataList.forEach((charData, idx) => {
charData.forEach((item) => {
const { src, index: positions } = item;
if (!resultMap[src]) {
resultMap[src] = Array(charDataList.length)
.fill(null)
.map(() => []);
}
resultMap[src][idx] = positions;
});
});
const matched = [];
for (const src in resultMap) {
const indicesArr = resultMap[src];
if (indicesArr.every((arr) => arr.length > 0)) {
let found = false;
indicesArr[0].forEach((pos) => {
let consecutive = true;
for (let i = 1; i < indicesArr.length; i++) {
if (!indicesArr[i].includes(pos + i)) {
consecutive = false;
break;
}
}
if (consecutive) found = true;
});
if (found) matched.push(src);
}
}
// 排序,对应的src格式为yyyy/mm/dd,自行调整
matched.sort((a, b) => {
const [ay, am, ad] = a.split("/");
const [by, bm, bd] = b.split("/");
return new Date(by, bm - 1, bd) - new Date(ay, am - 1, ad);
});
return matched;
}这里异步函数直接用await或者then就能拿到搜索结果,结果是src的数组,如下图。
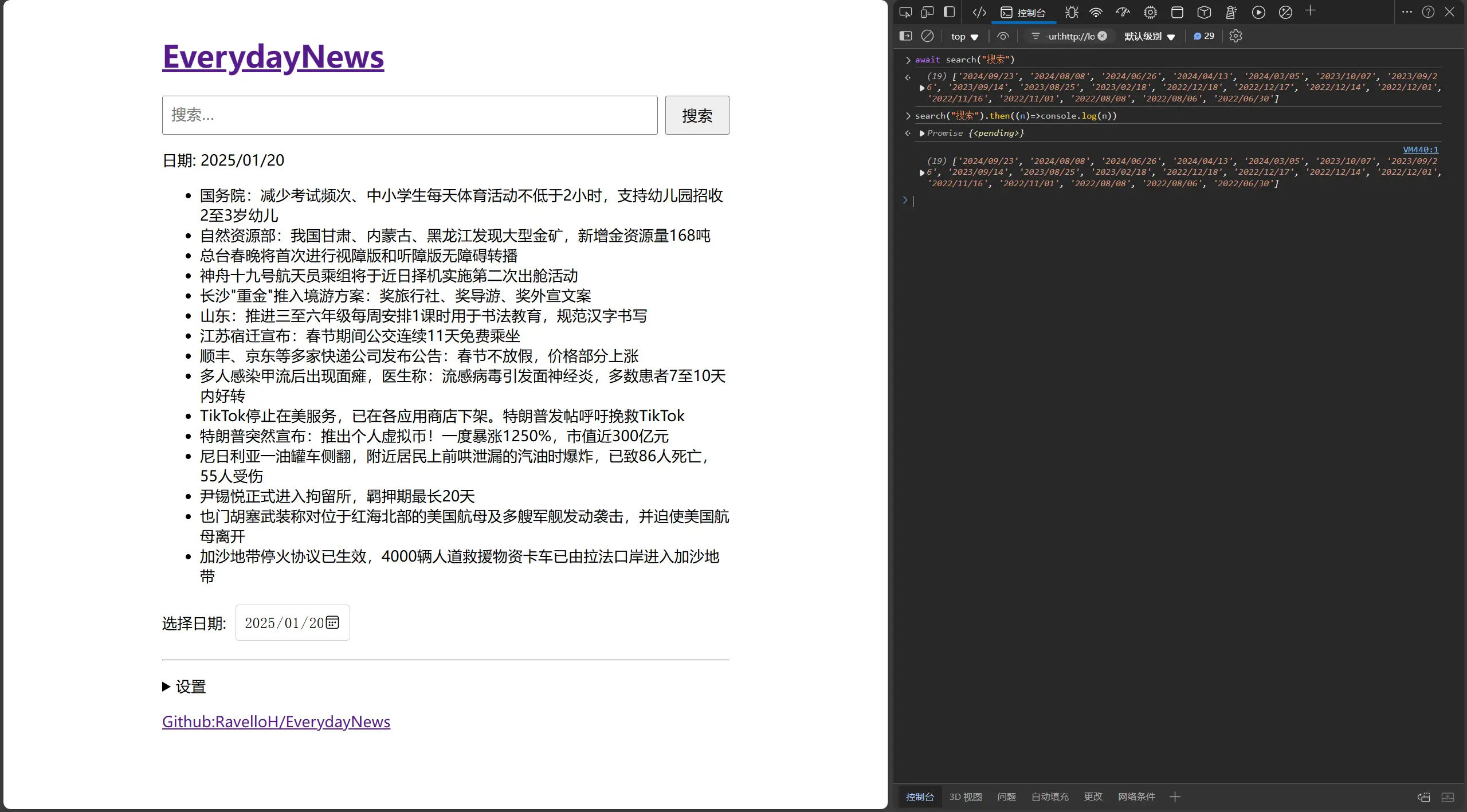 searchResult
searchResult
原理
用于生成索引的代码非常简单,可以直接去index-search/index.js at main · RavelloH/index-search看。
前端这个函数我写成了并发的,主要会把返回的json存到charDataList,随后按src组织成多维数组,形式大概如下:
{
src: [
[index,...], // 搜索词的第一个字出现的index
[index,...], // 以此类推
...
]
}很明显只需要判断此时所有数组非空(src对应content里有搜索词的每一个字),且index能按照连续顺序出现,即可说明搜索词在此src中出现。例:
[
[
0,
44,
385,
401
],
[
1,
259
],
[
2
]
]其中0 1 2连续,函数先遍历 [0,44,385,401],以其搜索其后第i个数组中是否包含数字n+i即可。
